核心概念
本章(C3)主要讲的是 Rust 核心概念, 因此需要前序学习.
Rust 有三大核心概念(或说是和其他语言的特有区分):
- Ownership
- Lifetime
- Fearless Concurrency
其中 Ownership + Lifetime(加上 Borrow Check 机制)共同构成 Rust 内存安全的基础.
理解 Lifetime 概念(Item 14)
Lifetime 和 Stack 紧密相关. 因此需要对程序运行过程中 Stack 的整体情况了如指掌, 才能真正理解 Lifetime.
当程序运行时, 从用户空间程序员的视角看, 程序的内存布局是这样的:
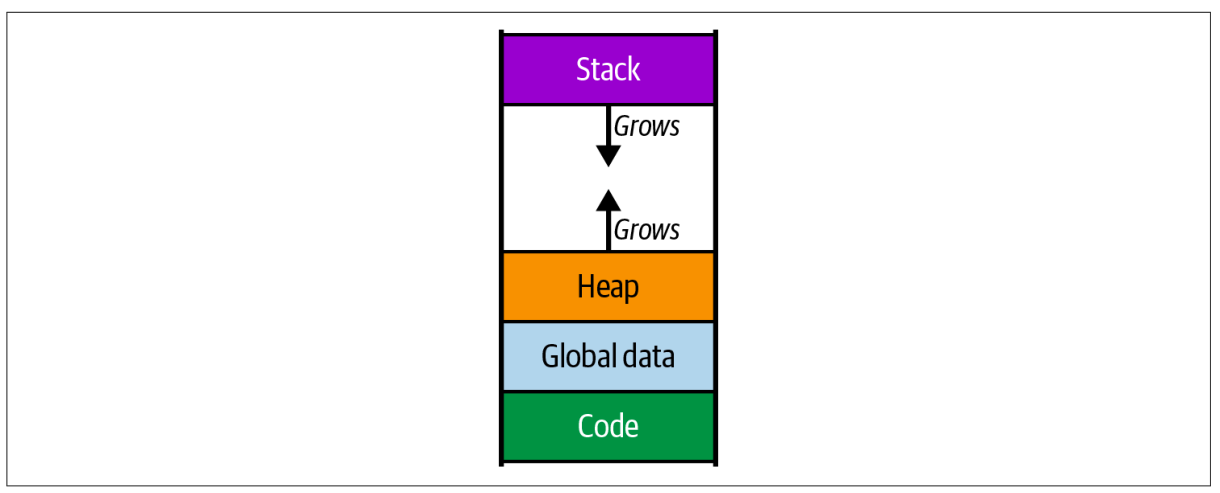
在 Stack 上, 存放程序函数调用的当前上下文环境. 一个栈帧中�可以存放有如下内容:
- 从调用者传递过来的函数参数
- 函数自己的本地变量
- 函数运行过程中产生的临时数据
- 函数的返回地址
例如我们有一个 f() 函数, 当其被调用后, 新的栈帧会被加入到当前线程对应的 Stack 上, 而 CPU 内的栈顶指针寄存器的值也会被改变为指向当前栈帧中.
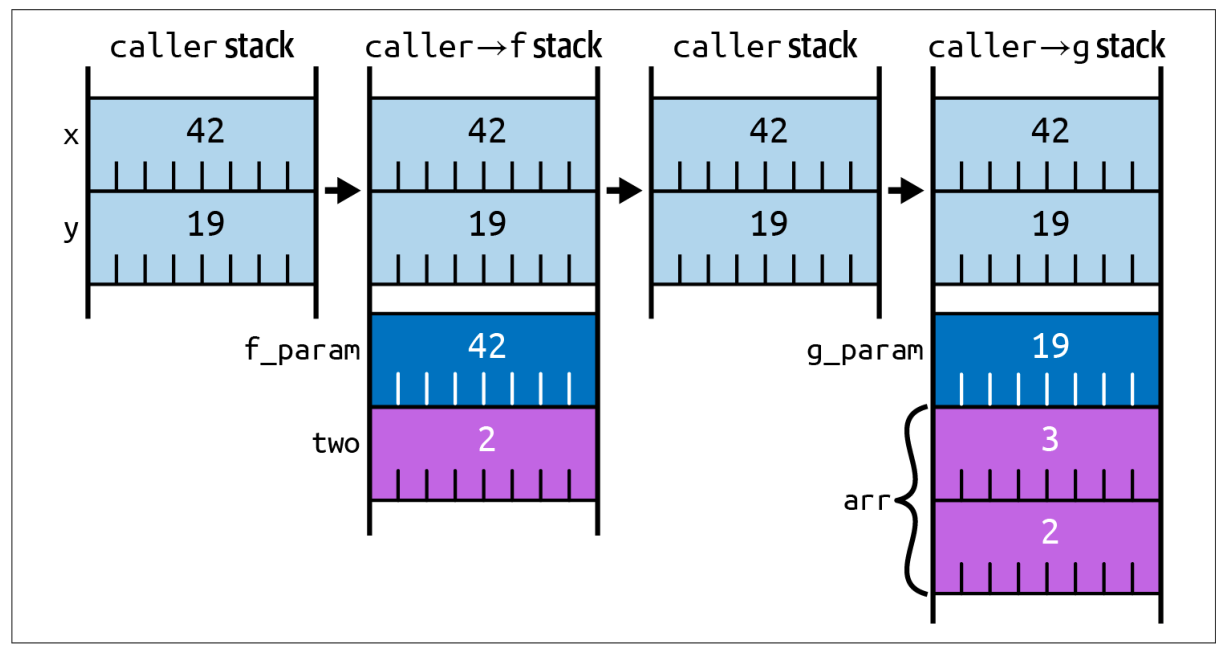
比如有如下的调用过程:
fn caller() -> u64 {
let x = 42u64;
let y = 19u64;
f(x) + g(y)
}
fn f(f_param: u64) -> u64 {
let two = 2u64;
f_param + two
}
fn g(g_param: u64) -> u64 {
let arr = [2u64, 3u64];
g_param + arr[1]
}
则栈上的变化如下所示(经过了大量简化后的概念理解图):
当某个栈帧被出栈后, 原有变量位��置的值是不确定的, 此时如果在某个栈帧中变量存放有指向该出栈后栈帧, 会有什么问题呢? 这个就是野指针的一种情况, 比如某个函数返回的是本地变量的一个引用(或指针), 当新的调用将该区域覆盖后, 此时的值就是一个不可预知的了.
在其他语言(比如 C 或 C++)中, 解决问题的办法就只有依靠开发者从代码结构层面上保证.
而 Rust 对这个问题的解决方案是引入 Lifetime, 即针对任何引用类型的变量, 其都关联有一个编译期所用的 Lifetime 标记, 用于传递给 borrow checker 进行检查.
引用的 Lifetime 指的是被引用的值能够保证不会被改变的最长维度, 也就是引用能够保证合法的最长维度, 当值被 move 或 drop 后, 生命期结束.
其中值被 move 的时机包括:
- 参数传递
- 参数返回
- 赋值(非 copy 类型)
move 可以是在栈上, 也可以是在 stack 和 heap 间.
而 drop 则是由编译器决定的(出作用域后, 同时开发者可以手动调用 mem::drop).
中间值的 drop 可以通过如下代码理解:
let x = f((a + b) * 2);
// 可以理解为:
let x = {
let temp1 = a + b;
{
let temp2 = temp1 * 2;
f(temp2)
} // `temp2` dropped here
}; // `temp1` dropped here
Lifetime 在 stack 上的原则就是根据 input(函数参数) 决定 output, 并且可以在没有 output 或有 self, 或单一参数时可以直接不用手写(三个规则).
假设是在 Heap 上的 Lifetime 又有什么规则呢?
在 heap 上的值的引用, 最终落脚点只有两种可能:
- 一系列的引用路径后, 回归到一个栈上的变量
- 一系列的引用路径后, 回归到一个 static 全局变量或手动 leak 的参数(
Box::leak)
因此只需要考虑的仍然是在栈上相同的情况.
此外, 如果是在结构体内有引用成员呢?
实际上引用链最终也会回归到栈上或全局变量, 但结构体上的引用较复杂, 如果不是为了极致的优化, 还是建议在 struct 中使用智能指针, 以便�于理解和使用, 即: 在 struct 中尽量让它拥有(own)自己的成员而非只是引用.
在 Rust 中还有一种情况, 当带引用成员的结构体作为返回值时, 如果是单参数函数或方法, 就可以自动忽略生命期标记. 但代码中体现出来就会有误导, 因此通常人为加上匿名生命期标记, 即 <'_> 便于阅读.
同时当在有 self 参数且可以自动忽略生命期标记时, 通常为其他参数加上匿名生命期标记, 以便说明其他参数的生命期和 self 是不同的.