RAG 和 LLM 简介
近期在调查 RAG + LLM 在 APP/网站 数据分析方向上的可行性和实践, 本文是一个记录性质的文章, 主要记录基础学习过程中的一些要点.
因此内容比较杂乱, 后续进行整理.
数据分析中 RAG + LLM 的应用可行性
看到一篇博客文章简单介绍了一种流程.
文章提到, 要掌握这种工作流程, 需要具备的前置知识:
- 了解 Python
- 了解数据分析基本概念
- 了解大语言模型的工作原理
- 一个能够工作的 LLM (可提供 API, 比如 Open AI)
这里先介绍大语言模型的基本工作原理(基于这个视频教程).
大语言模型介绍
以 llama 为例, 名字 llama-2-70b 的含义如下:
llama: meta 出品的 AI 大模型2: 第二次迭代的 llama70b: 参数为 700 亿
在 llama-2 这个模型族下, 包含了一系列不同参数个数的模型, 从 70 亿到 700 亿, 详见这里. 它的 Weight(或称 parameter), 架构, 论文都是开放的.
我们可以假设大语言模型(Large Language Model)由两个文件组成:
- 参数文件: 为这个大语言模型神经网络的参数, 每个参数存储为 2 字节(float16)
- 代码文件: 运行这个参数文件的代码
有了这两个文件, 实际整个运行基础就配齐了, 不需要其他任何东西, 不需要任何网络下载就能够在本机跑起来(和这个大语言模型对话), 当然因为单机性能, 可能无法跑起来 700 亿参数模型, 但 70 亿是可以的.

模型训练
关于大语言模型, 核心就是神经网络和参数. 其中神经网络算法及其架构和实现都是可以容易找到的, 不同大语言模型的区别主要在其参数上, 以及如何获取它们.
模型训练就是一个生成参数和调优参数, 进而获取到参数文件的过程.
比如我们通过互联网数据来训练 llama 模型(一个简化的例子):
- 比如首先通过不同网站收集到了大约 10 TB 的文本
- 准备好了一个 6000 GPU 的集群, 通过 12 天的时间训练
- 拿到一个 llama 270b 模型(花费 200 万美元)
训练的过程, 可以理解为将这 10TB 文本进行压缩, 但其是一种有损(非信息原样保留)压缩.

而神经网络的作用, 可以简单理解为是用于在输入的一系列词的基础上预测下一个词(prediction & compression), 要预测下一个词, 就需要针对这个词进行大规模的数据收集和压缩, 这些知识都被"压缩"到参数中.
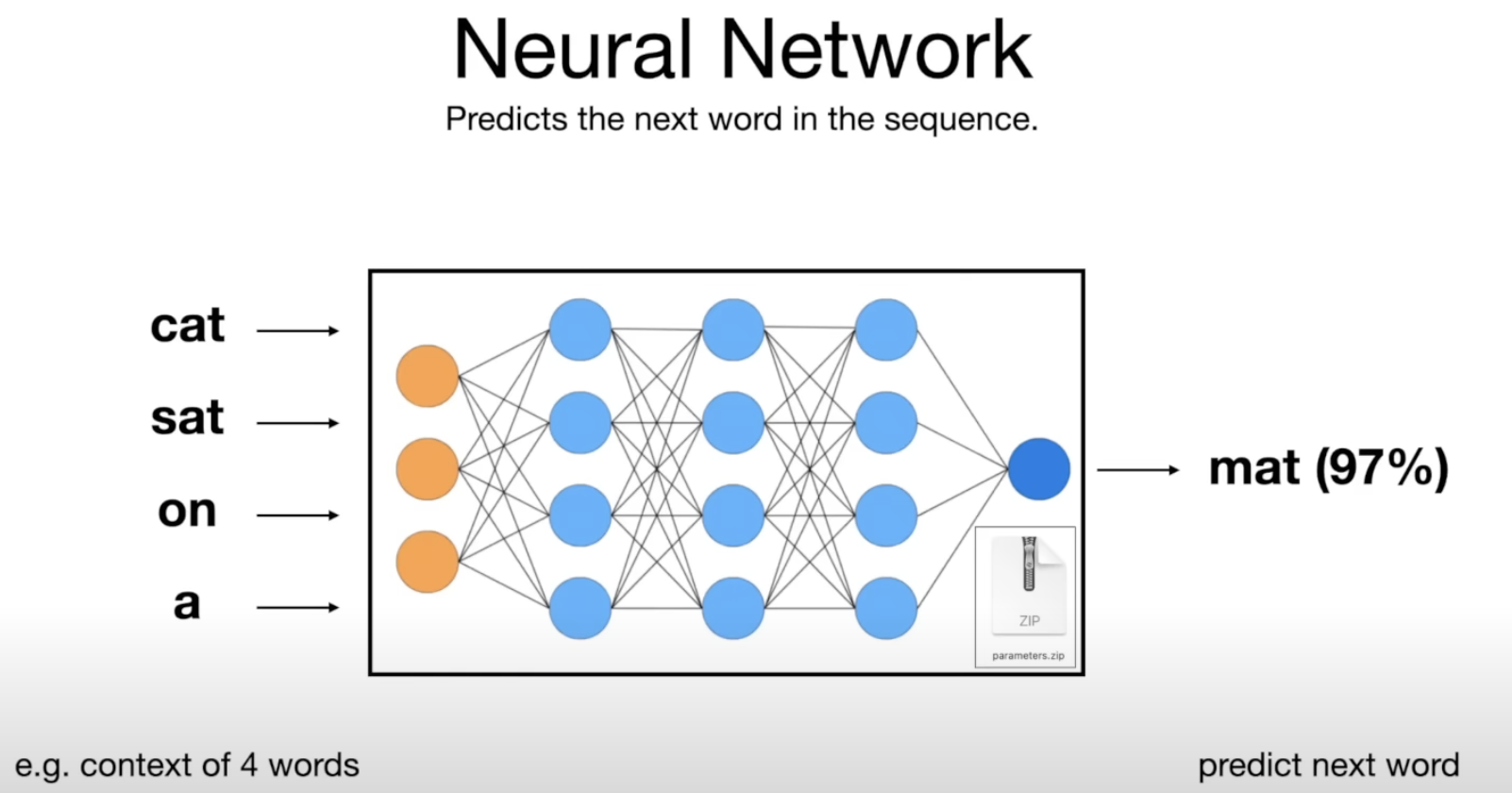
而大模型的输出更多可以理解为神经网络在参数所提供知识基础上的"幻想", 而这类神经网络都被称为 Transformer.
关于模型训练有三个阶段:
- 预训练(pre-training): 得到 base-model, 注重数据集数量, base-model 并非一个"直接可用(可给出响应)"的LLM.
- 调优(fine-tuning, 又称alignment): 得到 assistant model, 注重数据集质量, 经过这个阶段, 才是"可用的"LLM.
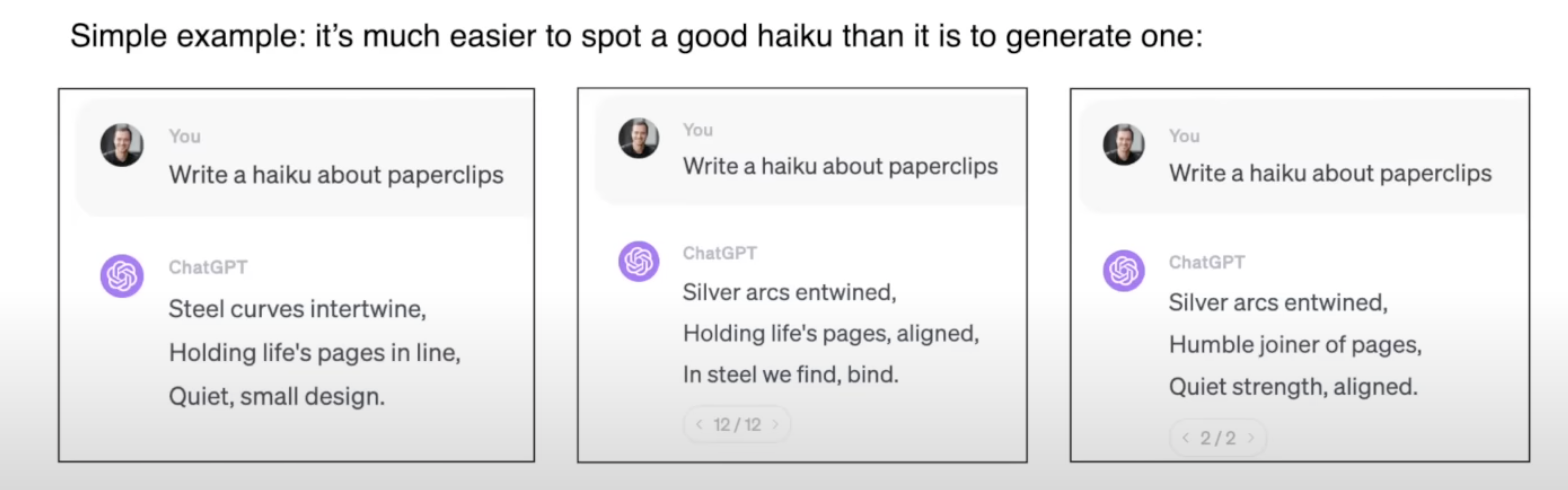
- RHF(reinforcement learning from human feedback): 提出问题 -> 针对 LLM 给出的候选结果中正确结果进行标记, 得到更为优化的模型.
形象比喻是: 预训练可以看作是生成了一个抽象的文本文档, 而调优引入了更多高质量数据后, 得到一个正确具体的 Q&A 文档.
许多大公司(比如 meta 的 llama)花费大量资源给出了 base model, 我们只需要再进行 fine-tuning.

RHF 的一个感官上的认识:
Tip: Hugging Face 有一个 LLM leaderboard, 有目前市面上绝大部分 LLM 的对比评分.
此外, 还有诸多 LLM 安全性和攻击方式需要注意.